Здравствуйте! Подскажите как определить, что текстовый файл в кодировке UTF8 или cp1251, если в нём нет BOM?
может есть функции в free-паскале ?
как определить кодировку UTF8?
Модератор: Модераторы

сравнить его с этой картинкой
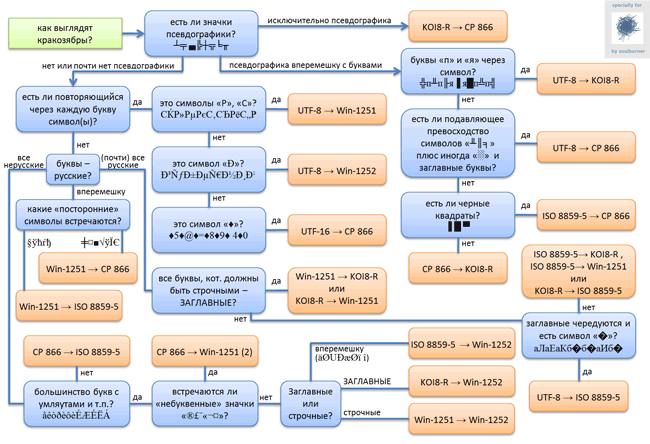
или попробовать http://chsdet.sourceforge.net/. Или воспользоваться : http://wiki.freepascal.org/UTF8_Tools. Если не ошибаюсь: последний то же может определить.
Ну или методом DYUMON. Или вики в подмогу, плюс на этом форуме есть ветки.
Ну или методом DYUMON. Или вики в подмогу, плюс на этом форуме есть ветки.

http://chsdet.sourceforge.net/ неправильно определяет если в тексте кириллица. С http://wiki.freepascal.org/UTF8_Tools. пока неразобрался
FindInvalidUTF8Character подойдёт.
мне нужно прочитать конфигурационный текстовый файл, и если он в кодировке cp1251 то преобразовать текст в UTF8
FindInvalidUTF8Character подойдёт.
мне нужно прочитать конфигурационный текстовый файл, и если он в кодировке cp1251 то преобразовать текст в UTF8
AlexEr81 писал(а):мне нужно прочитать конфигурационный текстовый файл, и если он в кодировке cp1251 то преобразовать текст в UTF8
При такой задаче: Можно попробовать смотреть длину буквы "а", если она равна 1, то это cp1251, ну а если 2, то это UTF8.
-
Лекс Айрин

- долгожитель
- Сообщения: 5717
- Зарегистрирован: 19.02.2013 16:54:51
- Откуда: Волгоград
- Контактная информация:
vitaly_l, в том то и проблема, что пока не определена кодировка нельзя сказать сколько места занимает символ.
Лекс Айрин писал(а):vitaly_l, в том то и проблема, что пока не определена кодировка нельзя сказать сколько места занимает символ.
Код: Выделить всё
procedure TForm1.Button1Click(Sender: TObject);
var str:string;
begin
str := 'йапона мать!';
if pos('а',str) = 3 then str := 'imUTF8' else str := 'imCp1251' ;
ShowMessage(str+' '+IntToStr(pos('а',str)));
end;
Последний раз редактировалось vitaly_l 14.04.2017 12:48:38, всего редактировалось 1 раз.
-
Лекс Айрин
- долгожитель
- Сообщения: 5717
- Зарегистрирован: 19.02.2013 16:54:51
- Откуда: Волгоград
- Контактная информация:
vitaly_l, попробуй. Только не забывай, что:
1) текст загружается с файла
2) строке, по большому счету, положить на кодировку.
3) А ты точно уверен, что размеры и положение в таблице символов конкретного тестового символа не совпадут для обеих проверяемых кодировок?
4)то, что в строке явная белиберда не означает, что пользователь ее не написал.
1) текст загружается с файла
2) строке, по большому счету, положить на кодировку.
3) А ты точно уверен, что размеры и положение в таблице символов конкретного тестового символа не совпадут для обеих проверяемых кодировок?
4)то, что в строке явная белиберда не означает, что пользователь ее не написал.
Лекс Айрин писал(а):А ты точно уверен, что размеры и положение в таблице символов конкретного тестового символа не совпадут для обеих проверяемых кодировок?
Русский символ: "а", в utf8 занимает - два символа, а в Cp1251 - один. На это можно смело опираться.
Лекс Айрин писал(а):попробуй. Только не забывай
Я показал как, а остальное: "дело мастера боится".
Добавлено спустя 222 минут 222 секунд:
Код: Выделить всё
procedure TForm1.Button1Click(Sender: TObject);
var str:string;
begin
str := Utf8ToWinCp('йапона мать!');
//str := 'йапона мать!';
if pos('а',str) = 3 then str := 'imUTF8' else str := 'imCp1251' ;
ShowMessage(str+' '+IntToStr(pos('а',str)));
end;-
Лекс Айрин
- долгожитель
- Сообщения: 5717
- Зарегистрирован: 19.02.2013 16:54:51
- Откуда: Волгоград
- Контактная информация:
vitaly_l писал(а):Русский символ: "а", в utf8 занимает - два символа, а в Cp1251 - один.
Это играет роль только если заранее известна кодировка. При том, что ansi может быть и в "широких" строках.
Лекс Айрин писал(а):Это играет роль только если заранее известна кодировка.
Ты что, пил с утра?
Получается, если кодировка конкретно Лексу и Айрину - заранее не известна, то буква "а" может занять любое кол-во символов в pos ? Это что-то типа, Корпускулярно-волнового дуализма
заранее неизвестно какие там будут буквы.. не перебирать же алфавит
где то видел способ про проверку на символ с кодом #0 дескать в utf8 его нет
-
Лекс Айрин
- долгожитель
- Сообщения: 5717
- Зарегистрирован: 19.02.2013 16:54:51
- Откуда: Волгоград
- Контактная информация:
vitaly_l писал(а):Получается, если кодировка конкретно Лексу и Айрину - заранее не известна, то буква "а" может занять любое кол-во символов в pos ?
Нет, мы просто (ни Лекс, ни Айрин) не знаем действительно ли найденный байт (или 2) это буква "а" ("б", "с", "д"...)
vitaly_l писал(а): Это что-то типа, Корпускулярно-волнового дуализма
типа того... символ Шредингера. При том, в общем случае, мы никак не можем определить кодировку. Программы анализа просто делают прогноз на основе определенной базы слов... если найдут хоть одно (2, 3,4...), то кодировка считается правильной. Иногда можно, конечно, предположить на основе определенных знаний о самой кодировке... Например, из-за наличия неестественно большого количества нулевых символов.